

TL;DR: Pico Prism 2.0 proves Ethereum mainnet blocks at an average of 6.1 seconds on the network’s current 60M gas limit, with 99.9% of blocks finalizing within the 12-second slot. The full setup runs on 16 RTX 5090 GPUs across two machines at roughly $100K in total hardware cost. Tested against Pico Prism 1.0 on the same 60M gas baseline, the new system delivers ~5.3x more proving efficiency per block.
In February, we previewed Pico Prism’s transition to a 16-GPU dual-machine setup, with early results on the same 45M gas benchmark blocks Pico Prism 1.0 had tested.
That transformation is now complete.
Pico Prism 2.0 is officially live, fully optimized, and benchmarked directly on the production 60M gas blocks Ethereum runs today.
The 2.0 release is a full-stack rebuild across the zkVM ISA, the distributed proving architecture, the emulator, and the GPU proving backend. The result is a system that proves larger blocks on a quarter of the hardware Pico Prism 1.0 used, faster on average, and lands squarely on the Ethereum Foundation’s headline real-time proving targets.
The Headline Results
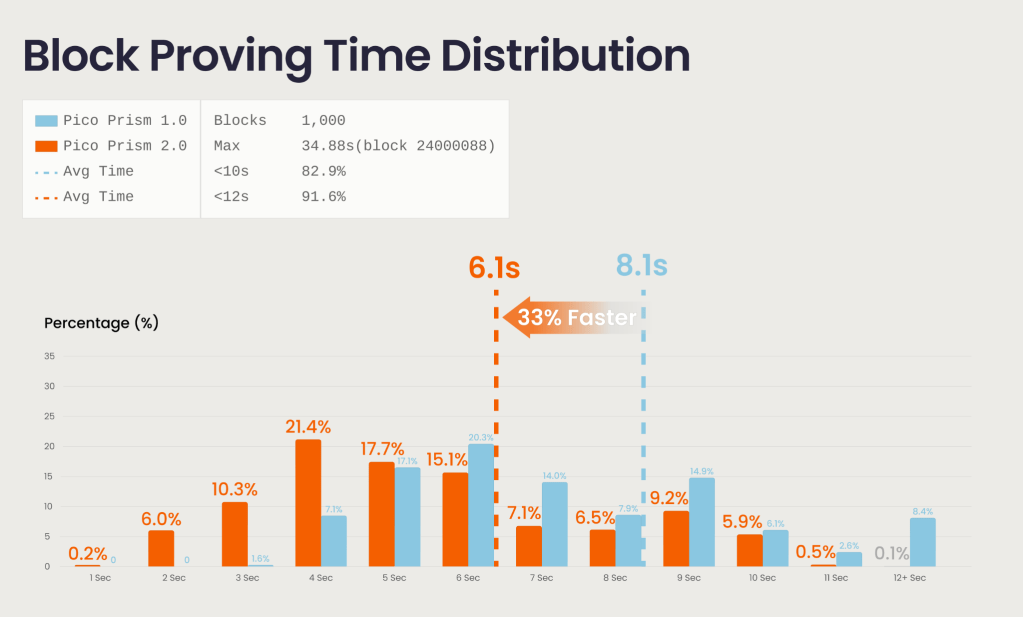
Pico Prism 2.0 was benchmarked on 1000 consecutive Ethereum mainnet blocks starting at block 24,000,000, on the network’s current 60M gas limit.
| Metric | Result |
| Average proving time | 6.1s |
| Blocks proven within 12s | 99.9% |
| Hardware | 16 RTX 5090 GPUs across 2 machines |
| Total hardware cost | ~$100K |
| Block gas limit | 60M (current Ethereum mainnet) |
For a fair head-to-head, Pico Prism 1.0’s 64-GPU configuration was re-tested on the same 60M gas blocks. The 1.0 system averages 8.1 seconds per proof. Pico Prism 2.0 hits 6.1 seconds on a quarter of the hardware, which works out to a ~5.3x improvement in compute work per block:
Pico Prism 1.0: 8.1s × 64 GPUs ÷ 60M gas = 8.64 GPU-seconds per million gas
Pico Prism 2.0: 6.1s × 16 GPUs ÷ 60M gas = 1.63 GPU-seconds per million gas
→ ~5.3× efficiency
Chief among the Ethereum Foundation’s real-time proving targets are sub-10-second average proving latency and on-prem hardware capex under $100K. Pico Prism 2.0 smashes both, running on consumer GPUs any team can buy off the shelf.
Benchmarks are fully reproducible. Binaries are available at https://github.com/brevis-network/pico-ethproofs.
Inside Pico Prism 2.0
Four upgrades land together in the 2.0 release. Each is significant on its own, and together they produce the 5x lift.
1. From RISC-V 32IM to RISC-V 64IM
Pico’s zkVM execution environment has moved to RISC-V 64IM, replacing the earlier 32-bit ISA. The 64-bit instruction set matches how real programs are written, giving Pico a richer execution environment and shorter execution traces on most workloads. The system trades a slightly more elaborate chip set for fewer cycles per program, and on real blocks, fewer cycles is what counts.
RISC-V 64IM is fully functional in Pico Prism 2.0. Formal verification of the new ISA implementation is underway.
2. A New Two-Machine Architecture
Pico Prism 2.0 runs on two machines, each with 8 RTX 5090 GPUs, connected over a 100 Gbps interconnect. At the center sits a global scheduler that operates as a shared task board for the proof pipeline. Both machines pull work dynamically from the scheduler rather than receiving statically partitioned assignments.
The architecture is built around three principles:
Global scheduling. Unfinished tasks live in a shared pool. Either machine can claim them as it frees up, which keeps GPUs busy instead of waiting on upstream work to complete.
Data locality. Each machine independently runs the same emulation and produces consistent local records. The scheduler only needs to dispatch task indices rather than heavy intermediate artifacts. Where local tasks are available, machines prefer them, keeping cross-machine traffic minimal.
Maximum parallelism. Combine and RISC-V chunk tasks are pulled from the proof tree dynamically, with autonomous load balancing across all 16 GPUs.
The result is a proving pipeline that behaves as a distributed work queue rather than a fixed sequence.
3. Ahead-of-Time Emulation
Pico Prism 1.0’s emulator interpreted programs at runtime, decoding and dispatching every instruction on the fly. The 2.0 emulator runs natively compiled Rust generated directly from ELF binaries, removing per-instruction decode and dispatch overhead entirely.
Frontend efficiency matters more than it sounds, because real-time proving is a balanced pipeline. If emulation can’t feed work to the GPUs fast enough, the GPUs sit waiting. AOT compilation removes a meaningful share of that frontend cost and keeps the proving stack continuously fed.
4. A Complete CUDA Rewrite
Pico’s GPU backend has been rewritten from the ground up, with deep optimization across the components that sit on the critical path of every proof. FRI commitment now uses adaptive LDE batch NTT, FRI opening uses Montgomery batch inversion, and quotient computation runs through a JIT compiler with an optimized constraint IR.
The rewritten stack delivers immediate speed gains and provides a cleaner, more extensible foundation for future GPU architectures and proving system advances.
Looking Ahead
The race to real-time Ethereum proving has been the defining challenge of the zkVM space for the past two years. In December 2025, the Ethereum Foundation declared the performance race effectively won and shifted focus to soundness foundations for L1 zkEVM integration through 2026.
Pico Prism 2.0 is the production system for the performance side. Going forward, work continues on the soundness side. Brevis is actively contributing alongside the EF’s security roadmap to ensure Pico Prism meets the 128-bit provable security target set for L1 zkEVM integration, with formal verification of the new RISC-V 64IM ISA already underway as part of that work.
In March 2026, Brevis was selected as one of four prover teams in the Ethereum Foundation’s On-Prem Proving Initiative through Ethproofs. The pilot funds the cohort to prove 1-in-10 Ethereum L1 blocks on self-owned hardware under real-world conditions, testing whether ZK proving can scale as decentralized infrastructure rather than depending on a handful of cloud providers. The program kicks off in May 2026 and is the closest thing yet to a dress rehearsal for live L1 zkEVM integration.
Each step on that path takes Pico Prism closer to ZK becoming part of Ethereum’s core infrastructure.
About Brevis
Brevis is a verifiable computing platform powered by zero-knowledge proofs, serving as the infinite compute layer for Web3. Applications can offload expensive computations off-chain while proving every result on-chain. The Brevis stack includes Pico zkVM for general-purpose computation, the ZK Data Coprocessor for trustless access to historical blockchain data, Pico Prism for real-time Ethereum block proving (99.8% coverage on 16 GPUs, hitting the Ethereum Foundation’s $100K hardware target), Vera for ZK-proven media authenticity, and ProverNet, the decentralized marketplace for ZK proof generation now running on mainnet. To date, Brevis has generated 340M+ proofs across 50+ protocols on 8+ blockchains.
Dive Deeper into Brevis:
Website | X | Discord | Pico zkVM | ZK Data Coprocessor | Incentra | ProverNet
Interested in building with Brevis? Reach out to us to explore ideas!
